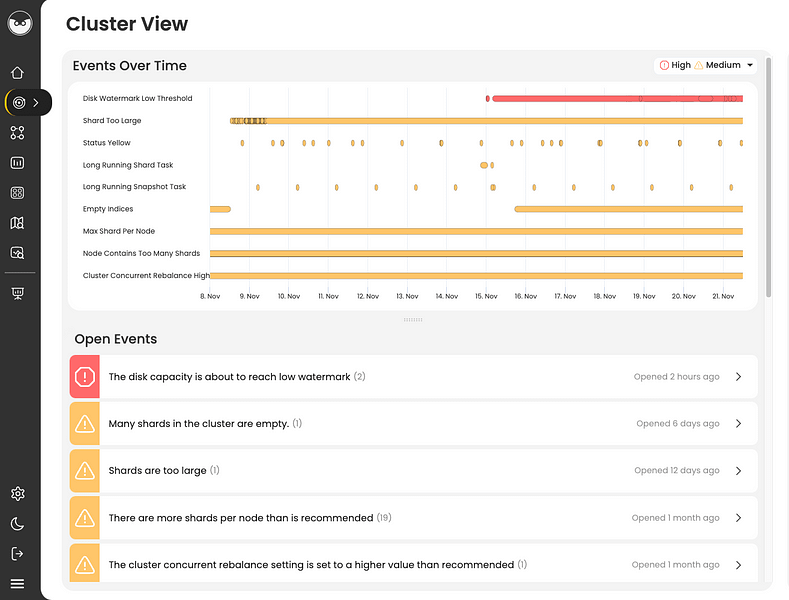
Before you begin reading this guide, we recommend you try running the Elasticsearch Error Check-Up which analyzes 2 JSON files to detect many configuration errors.
Briefly, this error occurs when there was a problem with creating the snapshot. This could be due to a variety of reasons such as disk space issues, network connectivity problems, or issues with the repository where the snapshots are stored. You will need to check the logs and resolve the issue before attempting the snapshot again.
To easily locate the root cause and resolve this issue try AutoOps for Elasticsearch & OpenSearch. It diagnoses problems by analyzing hundreds of metrics collected by a lightweight agent and offers guidance for resolving them.
Take a self-guided product tour to see for yourself (no registration required).
This guide will help you check for common problems that cause the log ” snapshot failed ” to appear. To understand the issues related to this log, read the explanation below about the following Elasticsearch concepts: recovery, indices and snapshot.
Overview
In Elasticsearch, recovery refers to the process of recovering an index or shard when something goes wrong. There are many ways to recover an index or shard, such as by re-indexing the data from a backup / failover cluster to the current one, or by restoring from an Elasticsearch snapshot. Alternatively, Elasticsearch performs recoveries automatically, such as when a node restarts or disconnects and connects again. There is an API to check the updated status of index / shard recoveries.
GET /<index>/_recoveryGET /_recovery
In summary, recovery can happen in the following scenarios:
- Node startup or failure (local store recovery)
- Replication of primary shards to replica shards
- Relocation of a shard to a different node in the same cluster
- Restoring a snapshot
Examples
Getting recovery information about several indices:
GET my_index1 GET my_index2/_recovery
Notes and good things to know
- When a node is disconnected from the cluster, all of its shards go to an unassigned state. After a certain amount of time, the shards will be allocated somewhere else on other nodes. This setting determines the number of concurrent shards per node that will be recovered.
PUT _cluster/settings{"transient":{"cluster.routing.allocation.node_concurrent_recoveries":3}}- You can also control when to start recovery after a node disconnects. This is useful if the node just restarts, for example, because you may not want to initiate any recovery for such transient events.
PUT _all/_settings{"settings":{"index.unassigned.node_left.delayed_timeout":"6m"}}- Elasticsearch limits the speed that is allocated to recovery in order to avoid overloading the cluster. This setting can be updated to make the recovery faster or slower, depending on your requirements.
PUT _cluster/settings{"transient":{"indices.recovery.max_bytes_per_sec":"100mb"}}Overview
An Elasticsearch snapshot is a backup of an index taken from a running cluster. Snapshots are taken incrementally. This means that when Elasticsearch creates a snapshot of an index, it will not copy any data that was already backed up in an earlier snapshot of the index (unless it was changed). Therefore, it is recommended to take snapshots often.
You can restore snapshots into a running cluster via the restore API. Snapshots can only be restored to versions of Elasticsearch that can read the indices. Check the version compatibility before you restore. You can’t restore an index to a cluster that is more than one version above the index version.
The following repository types are supported:
- File system location
- S3 object storage
- HDFS
- Azure and Google Cloud storage
Examples
An example of using S3 repository for Elasticsearch:
PUT _snapshot/backups
{
"type": "s3",
"settings": {
"bucket": "elastic",
"endpoint": "10.3.10.10:9000",
"protocol": "http"
}
}You will also need to set the S3 access key and secret key in Elasticsearch key store.
bin/elasticsearch-keystore add s3.client.default.access_key bin/elasticsearch-keystore add s3.client.default.secret_key
Taking a snapshot
Once the repo is set, taking a snapshot is just an API call.
PUT /_snapshot/backup/my_snapshot-01-10-2019
Where backup is the name of snapshot repo, and my_snapshot-01-10-2019 is the name of the snapshot. The above example will take a snapshot of all the indices. To take a snapshot of specific indices, provide the names of the indices you would like a snapshot of.
PUT /_snapshot/backup/my_snapshot-01-10-2019
{
"indices": "my_index_1,my_index_2"
}
}Restoring a snapshot
Restoring from a snapshot is also an API call:
POST /_snapshot/backup/my_snapshot-01-10-2019
/_restore
{
"indices": "index_1,index_2"
}This will restore index_1 and index_2 from the snapshot my_snapshot-01-10-2019 in backup repository.
Notes and good things to know
- Snapshot repository needs to be set up before you can take a snapshot, and you will need to install the S3 repository plugin as well if you plan to use a repository with S3 as backend storage.
sudo bin/elasticsearch-plugin install repository-s3
- You can use curator_cli tool to automate taking snapshots such as Cron, Kenkins or Kubernetes job schedule.
- It is better to use Elasticsearch snapshots instead of disk backups/snapshots. An index must be closed in order to be restored.
- Another option is to delete the index before restoring it. The snapshot and restore mechanism can also be used to copy data from one cluster to another cluster.
- If you don’t have S3 storage , you can run minio with NFS backend to create an S3 equivalent for your cluster snapshots

- When the operation is retried, it will only try to snapshot any shards that failed on the initial operation, until the snapshot succeeds.
- It is better to have the snapshot repo on the local network with Elasticsearch or configure/design the repository for high write throughput so that you don’t have to deal with partial snapshots.
- The snapshot operation will fail if there is a missing index. Setting the ignore_unavailable option to true will cause indices that do not exist to be ignored during snapshot operation.
- If you are using some open source security tool such as SearchGuard, you will need to configure the Elasticsearch snapshot restore settings on the cluster before you can restore any snapshot.
- In elasticsearch.yml:
searchguard.enable_snapshot_restore_privilege: true
Create data backups automatically without using snapshots
If having backups of your data is important to you and your operations, snapshots may not be ideal for you. Firstly, there are the problems mentioned above, but you also run the risk of losing any data generated in the time elapsed since the last snapshot was stored.
If, for example, you designate a snapshot and restore process to occur every 5 minutes, the data being backed up is always 5 minutes behind. If a cluster fails 4 minutes after the last snapshot was taken, 4 minutes of data will be completely lost.
Opster’s Multi-Cluster Load Balancer mirrors data to multiple clusters in real time to ensure complete data recovery, meaning there are zero time gaps and you’ll never run the risk of losing valuable data. To book a demo of the Mutli-Cluster Load Balancer, click here.
Log Context
Log “snapshot failed”classname is RecoverySourceHandler.java We extracted the following from Elasticsearch source code for those seeking an in-depth context :
final Engine.IndexCommitRef safeCommitRef;
try {
safeCommitRef = shard.acquireSafeIndexCommit();
resources.add(safeCommitRef);
} catch (final Exception e) {
throw new RecoveryEngineException(shard.shardId(); 1; "snapshot failed"; e);
}
// Try and copy enough operations to the recovering peer so that if it is promoted to primary then it has a chance of being
// able to recover other replicas using operations-based recoveries. If we are not using retention leases then we
// conservatively copy all available operations. If we are using retention leases then "enough operations" is just the
Find & fix Elasticsearch problems