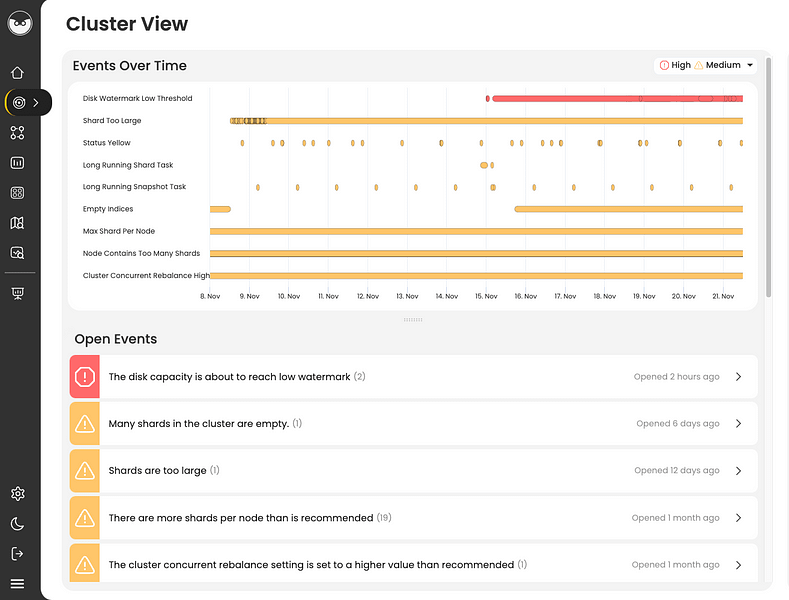
Before you begin reading this guide, we recommend you run Elasticsearch Error Check-Up which analyzes 2 JSON files to detect many errors.
To easily locate the root cause and resolve this issue try AutoOps for Elasticsearch & OpenSearch. It diagnoses problems by analyzing hundreds of metrics collected by a lightweight agent and offers guidance for resolving them. Take a self-guided product tour to see for yourself (no registration required).
This guide will help you check for common problems that cause the log ” Index no longer part of any snapshots in the repository; ” to appear. To understand the issues related to this log, read the explanation below about the following Elasticsearch concepts: blobstore, index, repositories, repository-azure and snapshots.
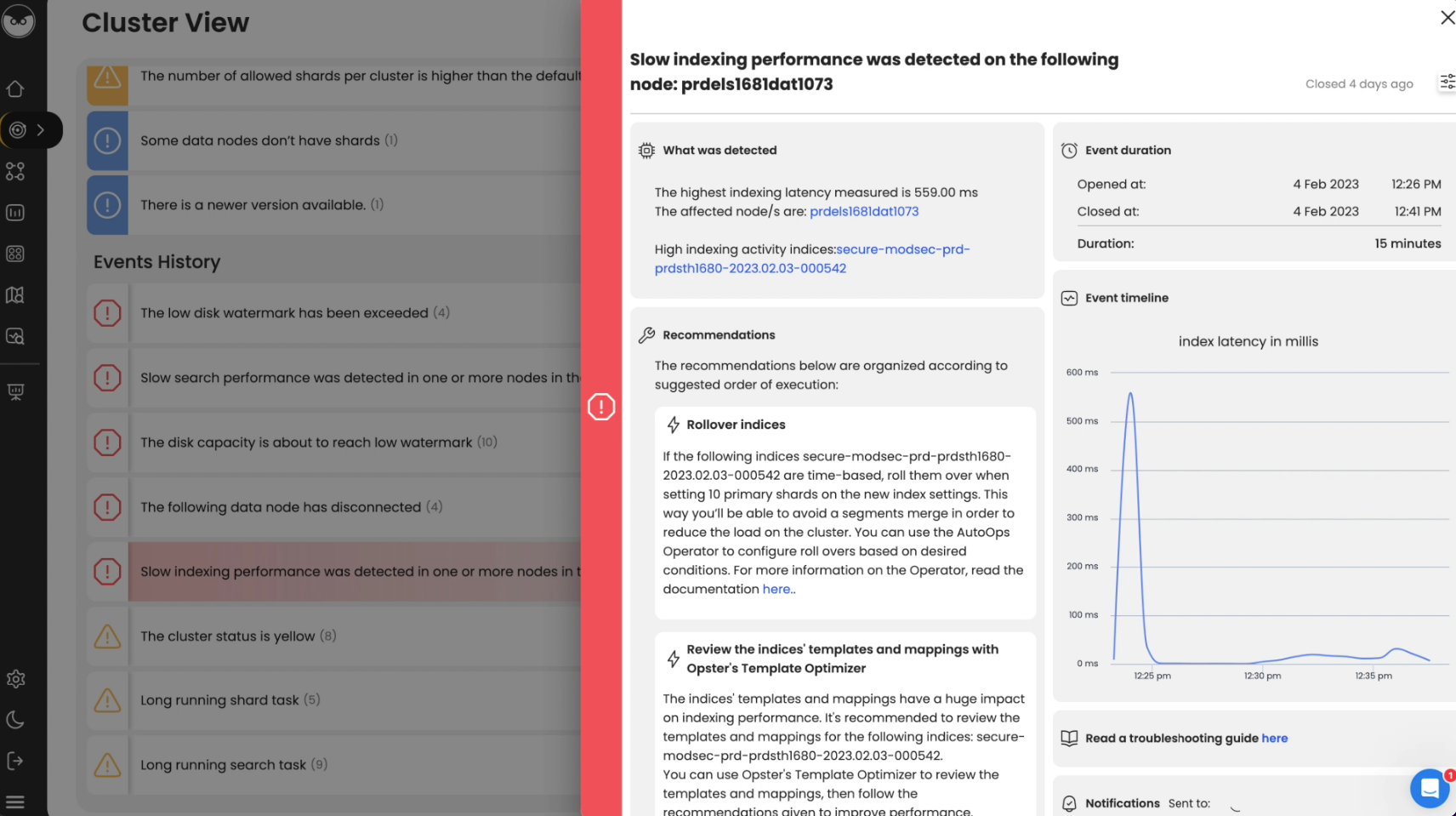
Overview
In Elasticsearch, an index (plural: indices) contains a schema and can have one or more shards and replicas. An Elasticsearch index is divided into shards and each shard is an instance of a Lucene index.
Indices are used to store the documents in dedicated data structures corresponding to the data type of fields. For example, text fields are stored inside an inverted index whereas numeric and geo fields are stored inside BKD trees.
Examples
Create index
The following example is based on Elasticsearch version 5.x onwards. An index with two shards, each having one replica will be created with the name test_index1
PUT /test_index1?pretty
{
"settings" : {
"number_of_shards" : 2,
"number_of_replicas" : 1
},
"mappings" : {
"properties" : {
"tags" : { "type" : "keyword" },
"updated_at" : { "type" : "date" }
}
}
}List indices
All the index names and their basic information can be retrieved using the following command:
GET _cat/indices?v
Index a document
Let’s add a document in the index with the command below:
PUT test_index1/_doc/1
{
"tags": [
"opster",
"elasticsearch"
],
"date": "01-01-2020"
}Query an index
GET test_index1/_search
{
"query": {
"match_all": {}
}
}Query multiple indices
It is possible to search multiple indices with a single request. If it is a raw HTTP request, index names should be sent in comma-separated format, as shown in the example below, and in the case of a query via a programming language client such as python or Java, index names are to be sent in a list format.
GET test_index1,test_index2/_search
Delete indices
DELETE test_index1
Common problems
- It is good practice to define the settings and mapping of an Index wherever possible because if this is not done, Elasticsearch tries to automatically guess the data type of fields at the time of indexing. This automatic process may have disadvantages, such as mapping conflicts, duplicate data and incorrect data types being set in the index. If the fields are not known in advance, it’s better to use dynamic index templates.
- Elasticsearch supports wildcard patterns in Index names, which sometimes aids with querying multiple indices, but can also be very destructive too. For example, It is possible to delete all the indices in a single command using the following commands:
DELETE /*
To disable this, you can add the following lines in the elasticsearch.yml:
action.destructive_requires_name: true
Overview
An Elasticsearch snapshot provides a backup mechanism that takes the current state and data in the cluster and saves it to a repository (read snapshot for more information). The backup process requires a repository to be created first. The repository needs to be registered using the _snapshot endpoint, and multiple repositories can be created per cluster. The following repository types are supported:
Repository types
| Repository type | Configuration type |
|---|---|
| Shared file system | Type: “fs” |
| S3 | Type : “s3” |
| HDFS | Type :“hdfs” |
| Azure | Type: “azure” |
| Google Cloud Storage | Type : “gcs” |
Examples
To register an “fs” repository:
PUT _snapshot/my_repo_01
{
"type": "fs",
"settings": {
"location": "/mnt/my_repo_dir"
}
}Notes and good things to know
- S3, HDFS, Azure and Google Cloud require a relevant plugin to be installed before it can be used for a snapshot.
- The setting, path.repo: /mnt/my_repo_dir needs to be added to elasticsearch.yml on all the nodes if you are planning to use the repo type of file system. Otherwise, it will fail.
- When using remote repositories, the network bandwidth and repository storage throughput should be high enough to complete the snapshot operations normally, otherwise you will end up with partial snapshots.
Log Context
Log “[{}] index [{}] no longer part of any snapshots in the repository;” classname is BlobStoreRepository.java.
We extracted the following from Elasticsearch source code for those seeking an in-depth context :
} catch (DirectoryNotEmptyException dnee) {
// if the directory isn't empty for some reason; it will fail to clean up;
// we'll ignore that and accept that cleanup didn't fully succeed.
// since we are using UUIDs for path names; this won't be an issue for
// snapshotting indices of the same name
logger.warn(() -> new ParameterizedMessage("[{}] index [{}] no longer part of any snapshots in the repository; " +
"but failed to clean up its index folder due to the directory not being empty."; metadata.name(); indexId); dnee);
} catch (IOException ioe) {
// a different IOException occurred while trying to delete - will just log the issue for now
logger.warn(() -> new ParameterizedMessage("[{}] index [{}] no longer part of any snapshots in the repository; " +
"but failed to clean up its index folder."; metadata.name(); indexId); ioe);
Find & fix Elasticsearch problems